From pilot to production without sending sensitive data outside your network. Everything is self-hosted, governed, and ready for enterprise rollout.
💬
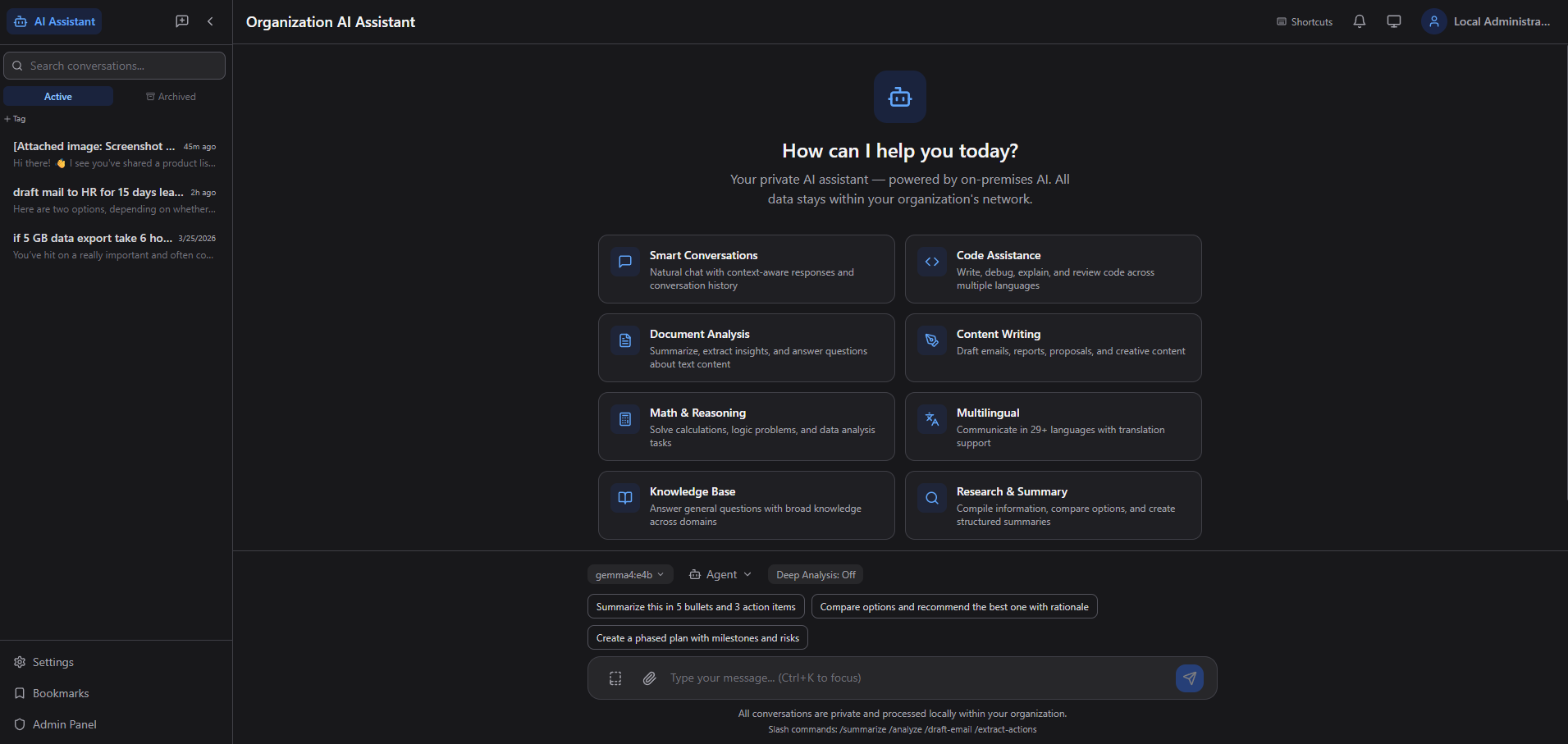
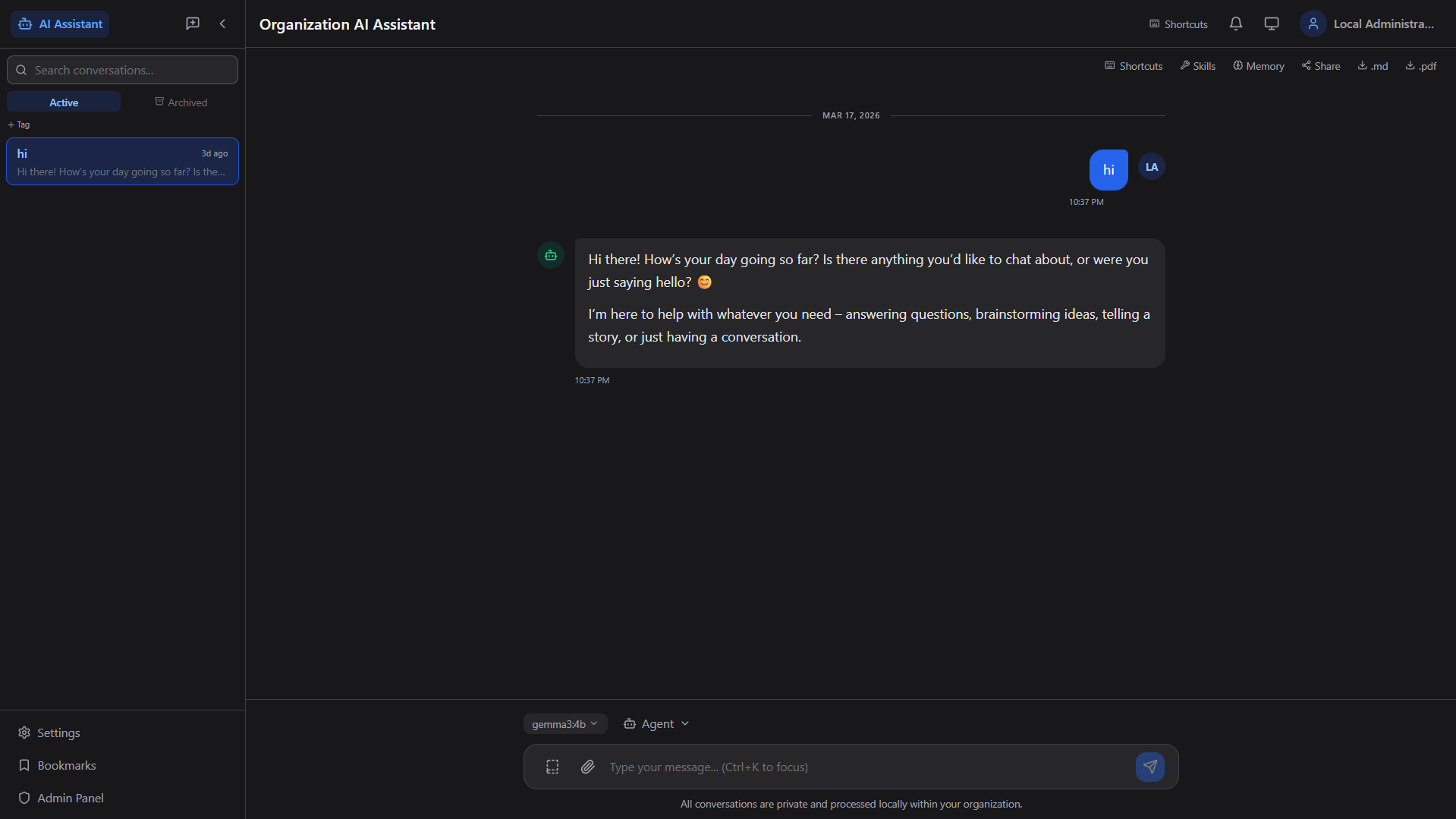
Smart Conversations
Real-time streaming chat with context-aware responses, conversation history, search, tagging, archiving, and keyboard shortcuts.
🤖
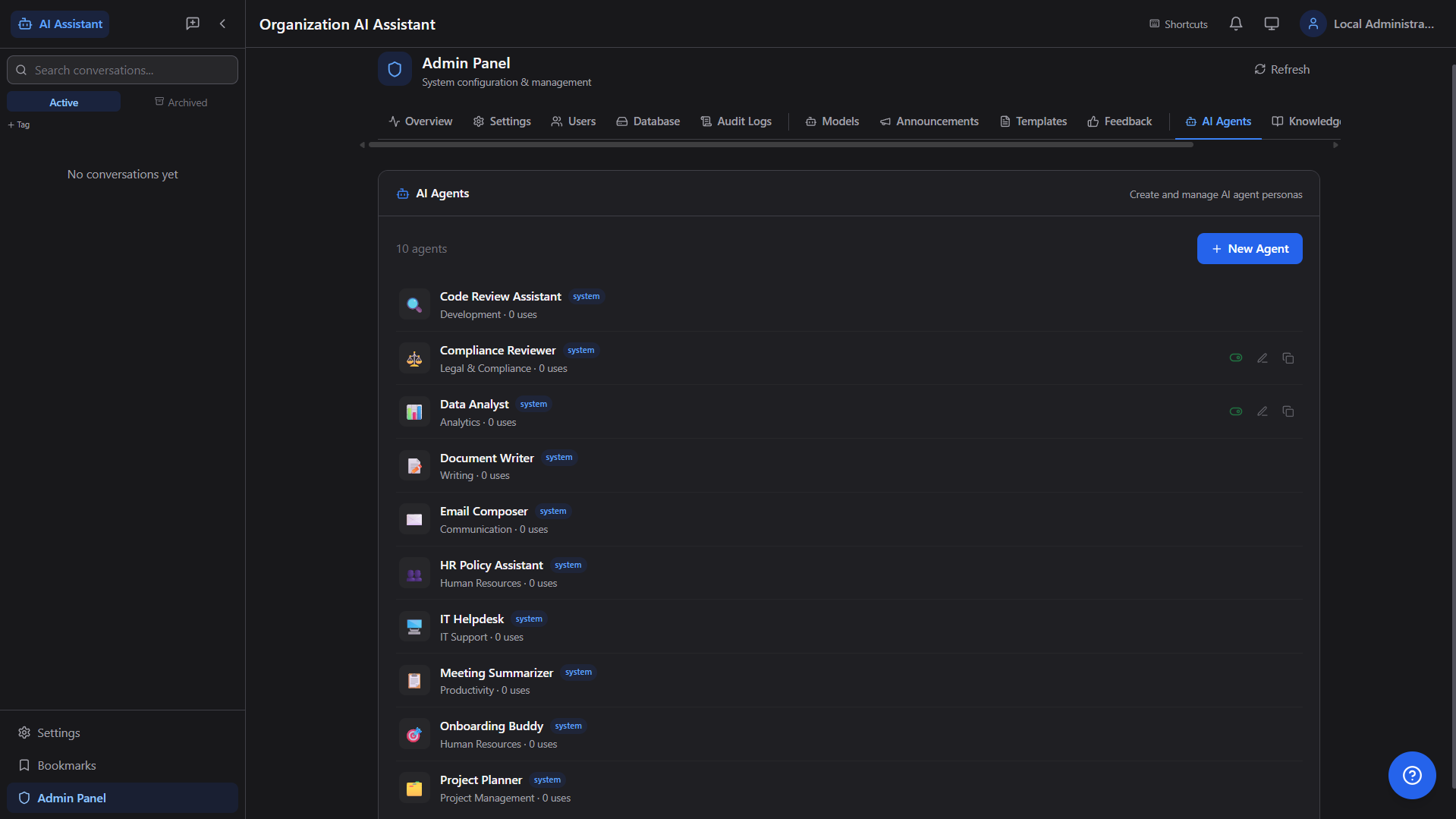
AI Agents
10+ specialized personas — Code Reviewer, Data Analyst, HR Policy, IT Helpdesk, Document Writer — each with custom system prompts and behavior.
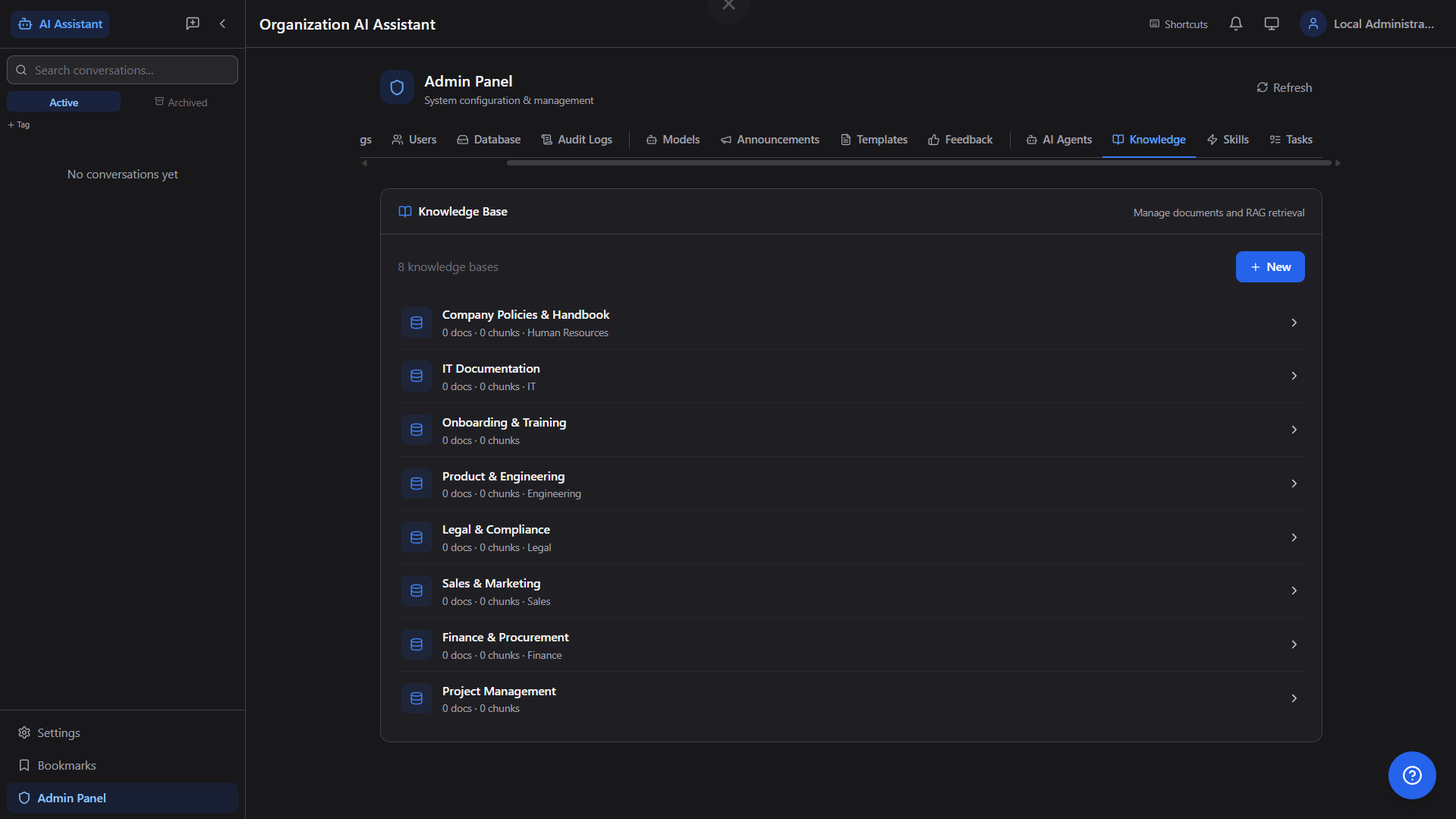
📚
RAG Knowledge Base
Upload company documents (PDF, DOCX, PPTX, XLSX), auto-chunk and embed, then query them in natural language with source citations.
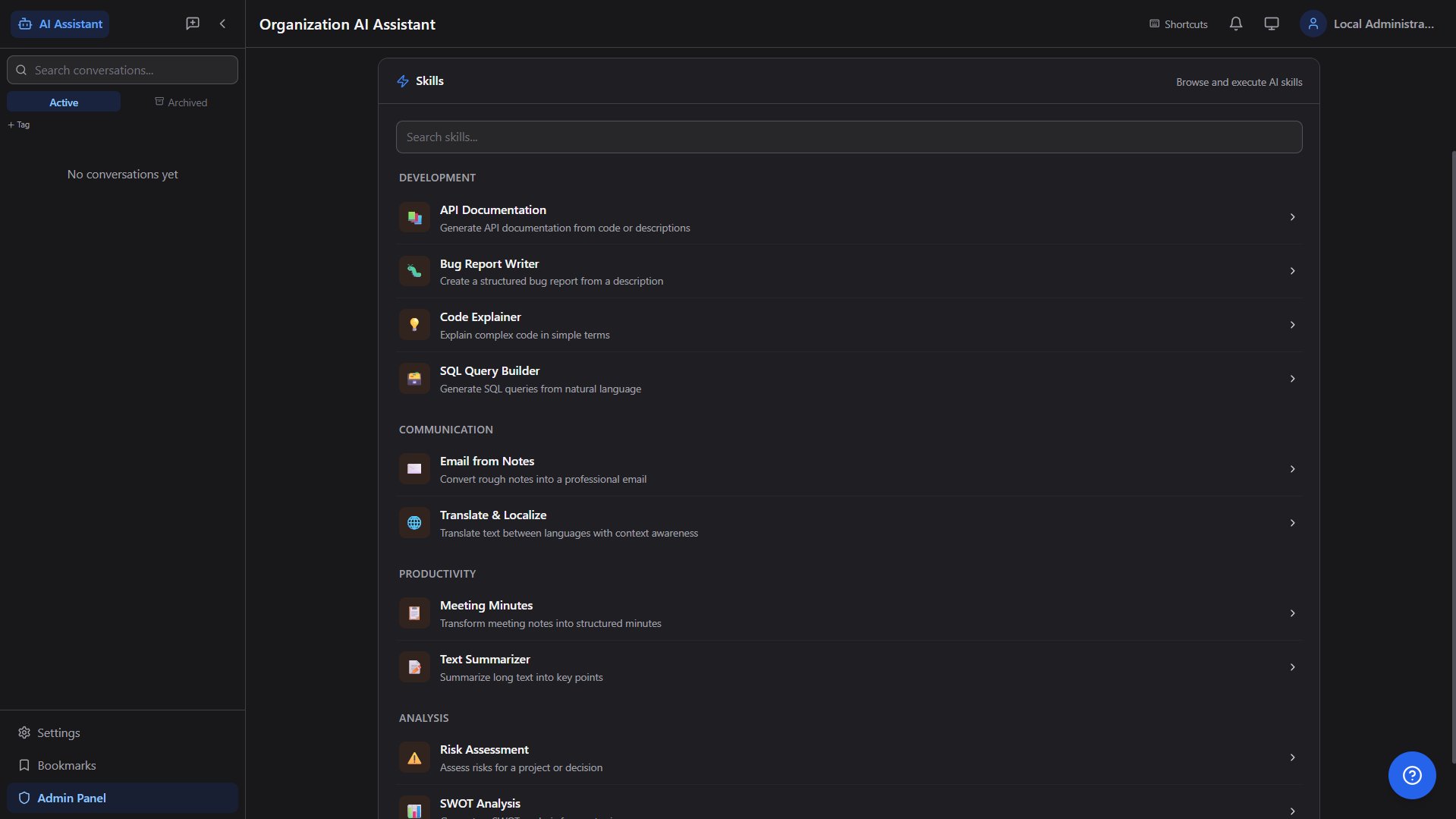
⚡
Skills Engine
Pre-built multi-step AI workflows — API Docs Generator, Bug Report Writer, SQL Builder, Meeting Minutes, SWOT Analysis, and more.
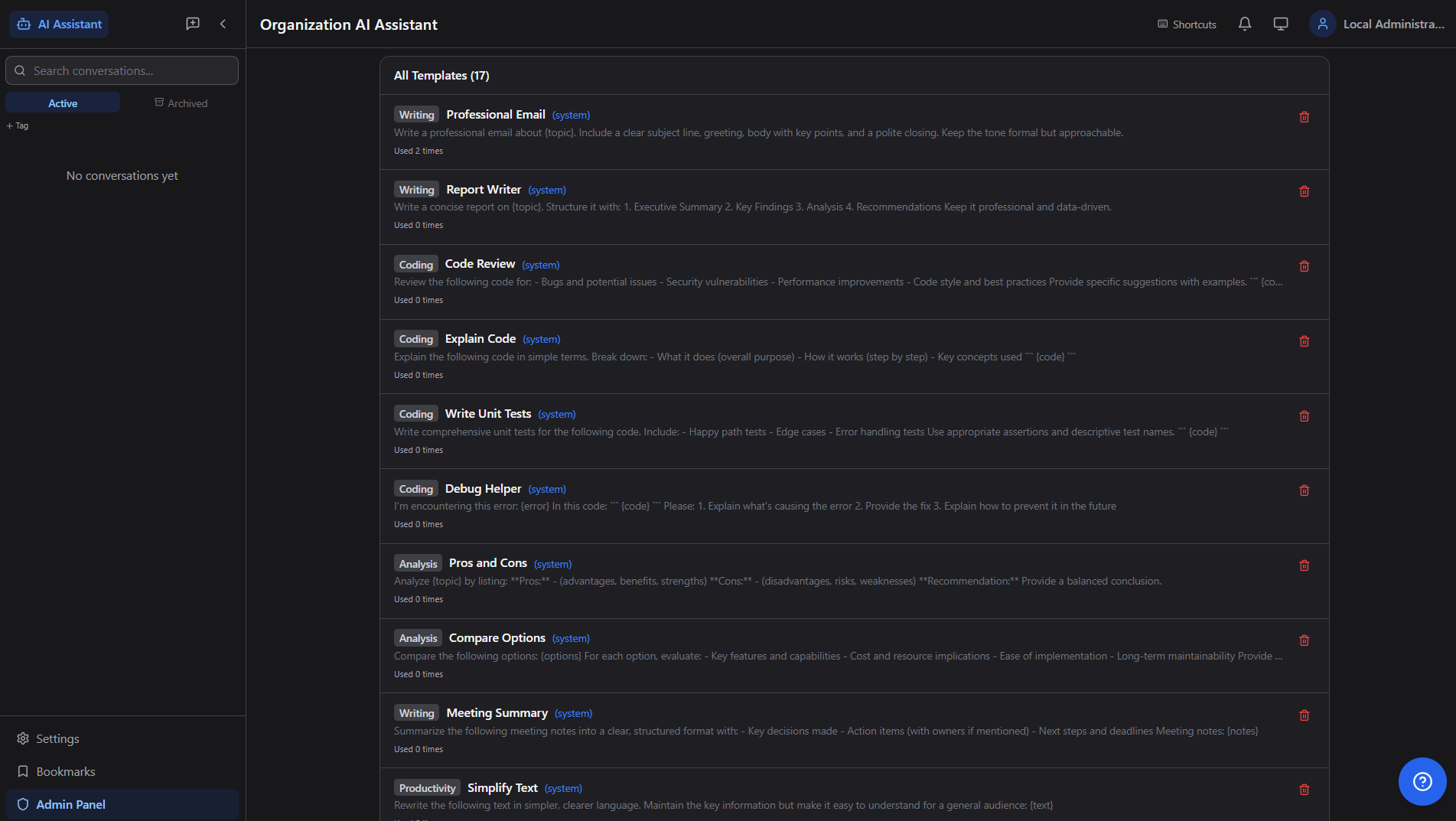
📄
Prompt Templates
17+ system templates (Writing, Coding, Analysis, Productivity) — one-click reuse for Professional Email, Code Review, Report Writer, etc.
🧠
AI Memory
Persistent memory across conversations — user preferences, facts, and context. Auto-extract or manually add memories per user, department, or org.
📎
File Attachments
Attach images and documents directly to chat. AI analyzes uploaded files (PDF, Word, Excel, PowerPoint, HTML) with full text extraction.
📦
Export (.md / .pdf)
Export individual conversations as styled PDF or Markdown. Bulk export all conversations as a timestamped ZIP archive for compliance.
🔗
Conversation Sharing
Share conversations with colleagues via secure internal links. Bookmark important messages, tag conversations for easy retrieval.
🛠
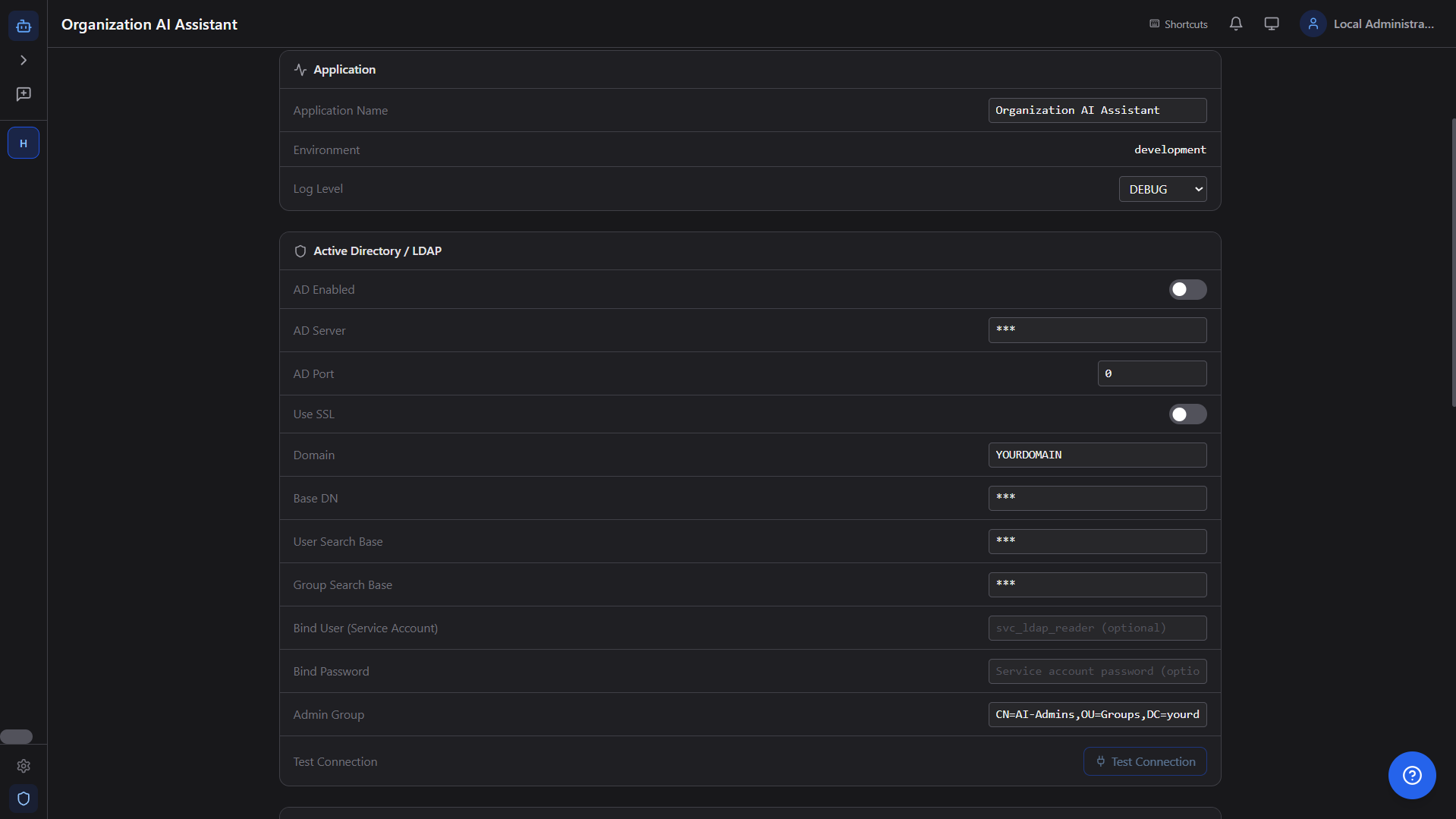
Admin Panel (15 Tabs)
Comprehensive control plane for system operations, content governance, and AI automation. Feature-flag aware UI ensures clean, reliable admin workflows.
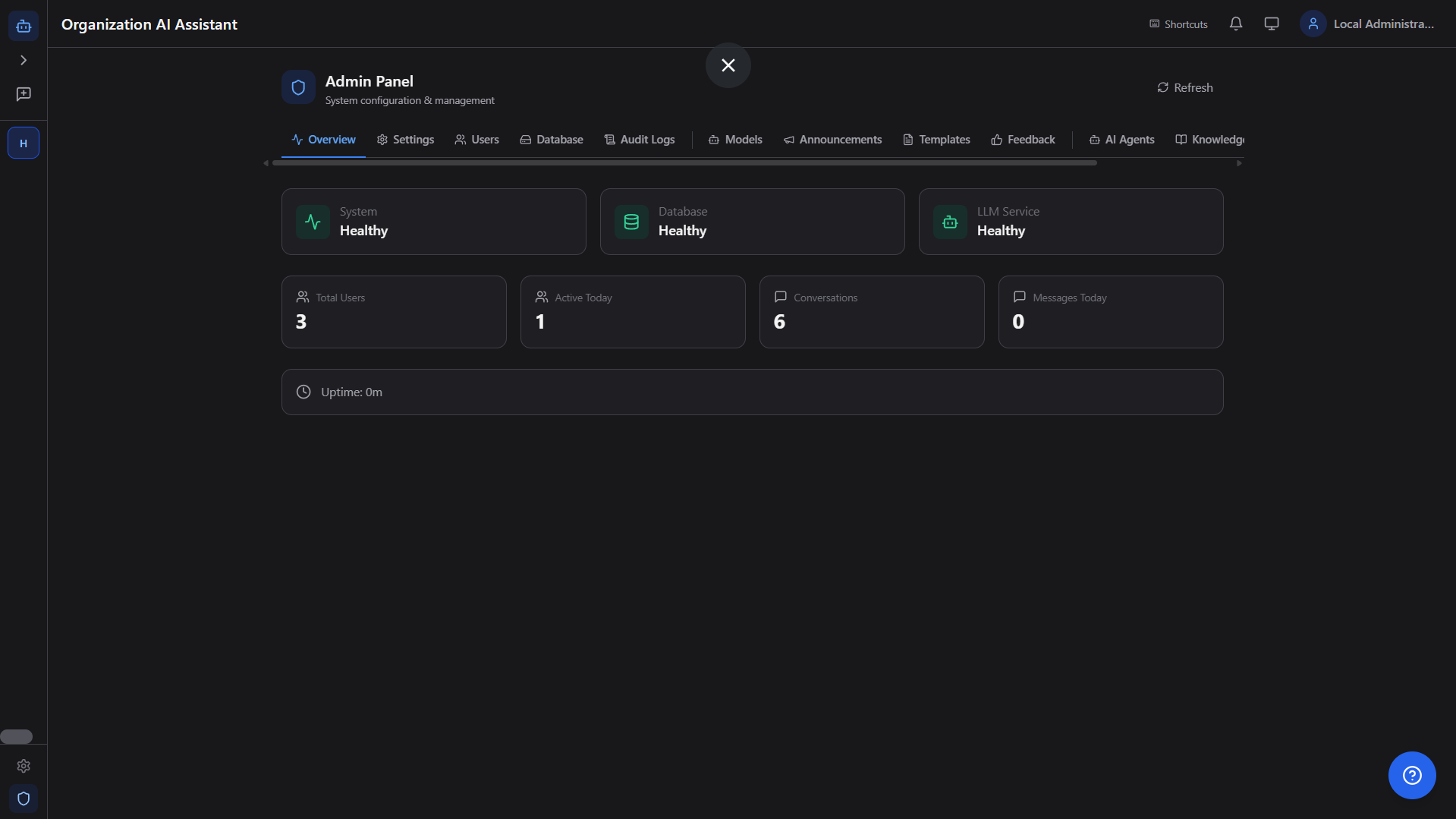
📊
Health Dashboard
Real-time system health monitoring — database, LLM service, uptime, active users, total conversations, and message counts at a glance.
🗃
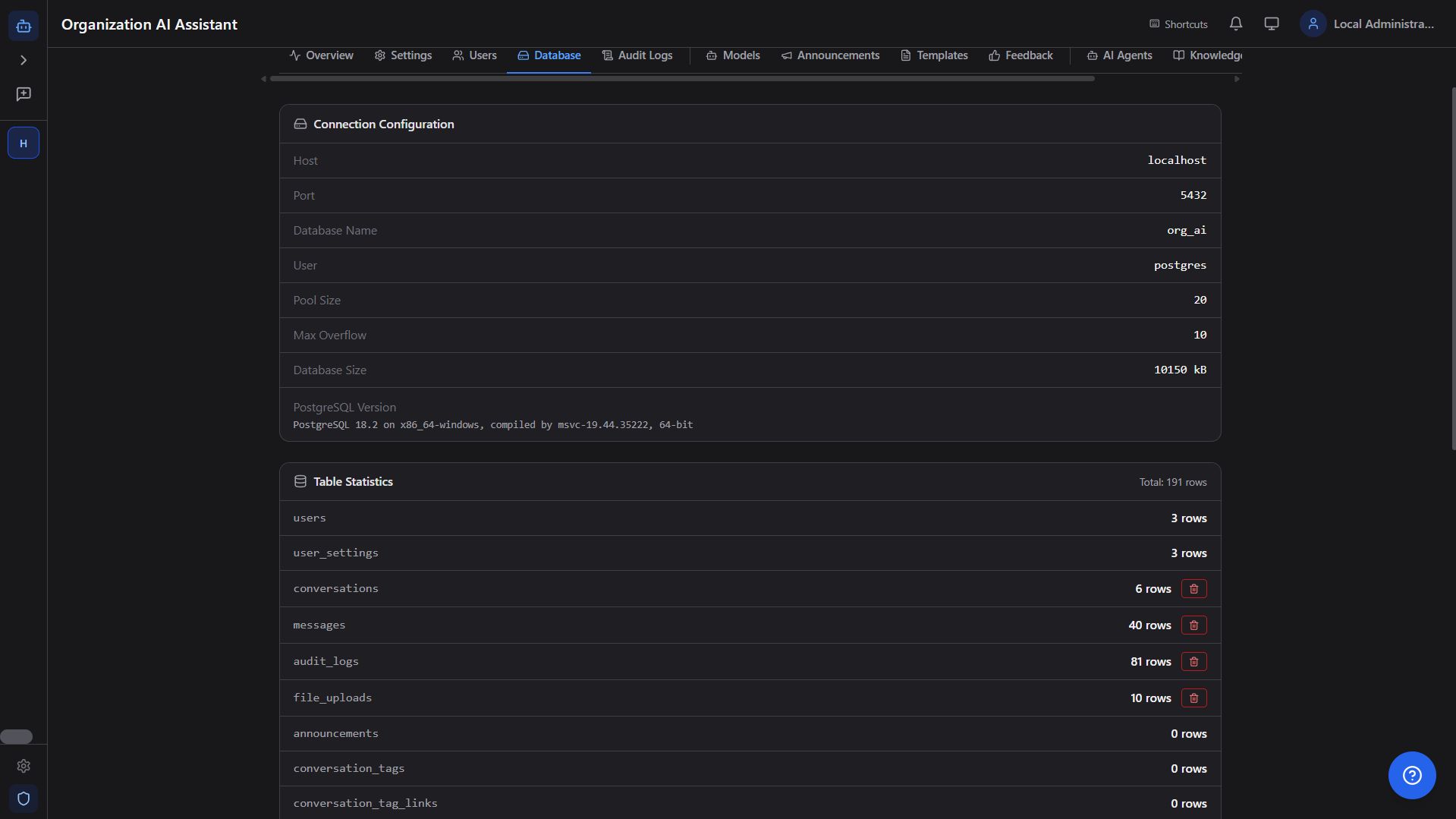
Database Management
Full backup/restore across mapped tables including organization mappings, connection stats, table row counts, and per-table clear controls.
🎓
Model Management
Pull, switch, and delete Ollama models from the admin UI. Configure temperature, max tokens, context window, GPU layers per model.
📅
Scheduled Tasks
Background job scheduler with cron expressions — automated reports, data cleanup, periodic notifications. Full execution history and error logs.
🔔
Notifications & Announcements
In-app notification center and organization-wide announcements. Push alerts from scheduled tasks, admin broadcasts, and system events.
🔍
Eval Dashboard & Trace Timeline
Inspect request phases, model routing, retrieval activity, retries, and completion latency to improve quality and reduce operational blind spots.
✅
Approval-Gated Actions
Idempotent action requests with approve/reject/execute controls for safer automation in regulated environments and change-managed operations.